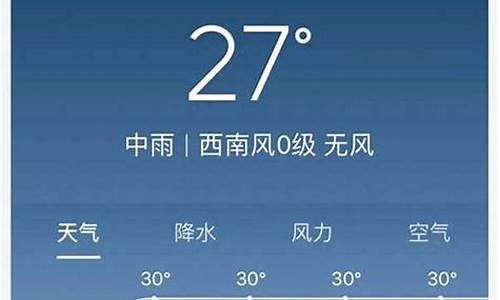
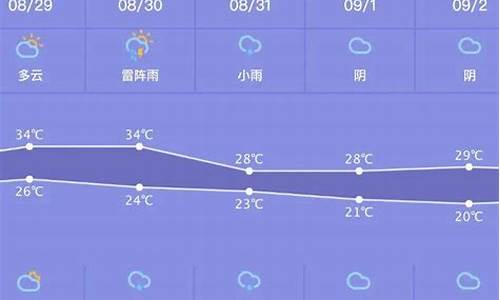
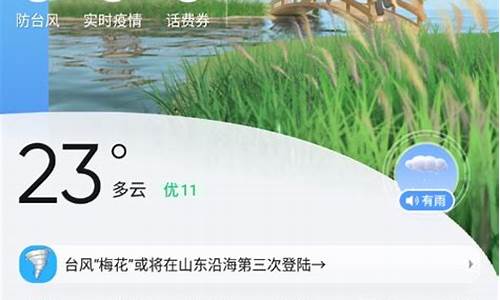
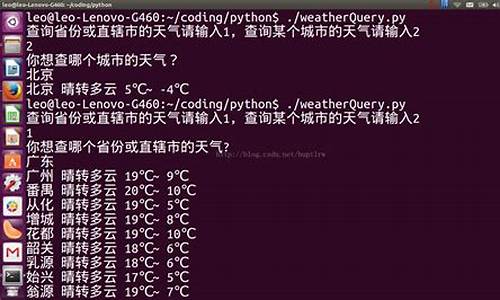
python3爬虫天气预报_python天气预报代码
1.Python有多少版本(2023年最新整理)
python做科学计算的特点:1. 科学库很全。(推荐学习:Python教程)
科学库:numpy,scipy。作图:matplotpb。并行:mpi4py。调试:pdb。
2. 效率高。
如果你能学好numpy(array特性,f2py),那么你代码执行效率不会比fortran,C差太多。但如果你用不好array,那样写出来的程序效率就只能呵呵了。所以入门后,请一定花足够多的时间去了解numpy的array类。
3. 易于调试。
pdb是我见过最好的调试工具,没有之一。直接在程序断点处给你一个截面,这只有文本解释语言才能办到。毫不夸张的说,你用python开发程序只要fortran的1/10时间。
4. 其他。
它丰富而且统一,不像C++的库那么杂(好比pnux的各种发行版),python学好numpy就可以做科学计算了。python的第三方库很全,但是不杂。python基于类的语言特性让它比起fortran等更加容易规模化开发。
数值分析中,龙格-库塔法(Runge-Kutta methods)是用于非线性常微分方程的解的重要的一类隐式或显式迭代法。这些技术由数学家卡尔·龙格和马丁·威尔海姆·库塔于1900年左右发明。
龙格-库塔(Runge-Kutta)方法是一种在工程上应用广泛的高精度单步算法,其中包括著名的欧拉法,用于数值求解微分方程。由于此算法精度高,取措施对误差进行抑制,所以其实现原理也较复杂。
高斯积分是在概率论和连续傅里叶变换等的统一化等计算中有广泛的应用。在误差函数的定义中它也出现。虽然误差函数没有初等函数,但是高斯积分可以通过微积分学的手段解析求解。高斯积分(Gaussian integral),有时也被称为概率积分,是高斯函数的积分。它是依德国数学家兼物理学家卡尔·弗里德里希·高斯之姓氏所命名。
洛伦茨吸引子及其导出的方程组是由爱德华·诺顿·洛伦茨于1963年发表,最初是发表在《大气科学杂志》(Journal of the Atmospheric Sciences)杂志的论文《Deterministic Nonperiodic Flow》中提出的,是由大气方程中出现的对流卷方程简化得到的。
这一洛伦茨模型不只对非线性数学有重要性,对于气候和天气预报来说也有着重要的含义。行星和恒星大气可能会表现出多种不同的准周期状态,这些准周期状态虽然是完全确定的,但却容易发生突变,看起来似乎是随机变化的,而模型对此现象有明确的表述。
更多Python相关技术文章,请访问Python教程栏目进行学习!以上就是小编分享的关于python能做什么科学计算的详细内容希望对大家有所帮助,更多有关python教程请关注环球青藤其它相关文章!
Python有多少版本(2023年最新整理)
今天给各位分享django如何实现异步视图的知识,其中也会对django 异步orm进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:
1、Django里面怎么实现数据库视图啊 就是虚拟表2、Python 语言Django 框架的简化视图3、python3.7 中使用django-celery 完成异步任务4、Django配置Celery执行异步和同步任务(tasks))5、django中异步任务除了celery还有什么?6、Django中怎么使用django-celery完成异步任务Django里面怎么实现数据库视图啊 就是虚拟表正经回答:先在数据库中建立好视图,然后django中建立对应的model。表所对应的类下面再建立一个Meta类,大致如下
class?ViewModel(models.Model):
"""这个model类对应你所建立好的视图"""
class?Meta(object):
"""同理,该方法可用于使用mysql中任何已有的表,不仅是视图"""
db_table?=?'your_view'?#显式指定表名,也就是你建立的视图的名字
managed?=?false?#默认是ture,设成false?django将不会执行建表和删表操作
#?建立字段间的映射
#?需要注意的是,必须设一个字段为主键
#?不然django会自动创建一个id字段为主键,引发错误
百度知道越来越辣鸡了,全是答非所问的。
Python 语言Django 框架的简化视图
1 我们在用Django编程时,会发现,经常需要用到列表、详情、修改这些操作。这些操作 几乎可以满足数据编辑的大部分要求。那能不能像YII2脚手架功能一样直接提供一个通用的模板类,只需指定几个必要的参数,所有的功能自己去实现呢。
2 Python 语言Django 框架,刚好提供这样的功能, 它有很多叫法,如 类视图、通用视图、简化视图,都指的是它。我们可以把它看成 Django 框架的脚手架。
3 Django简化视图底层的本质是通过从URL传递过来的参数去数据库查询数据,加载一个模板,利用得到的数据渲染模板(按照路由、视图、模板、模型的路线图)。
4 以下是Django 框架提供的简化视图,可以直接拿来使用。
View ------------------- 所有类视图的基类
TemplateView --------------渲染一个template
RedirectView ----------------重定向类视图
通用显示视图Display view:
DetailView ---------------展示单个object
ListView ------------------展示多个object
通用编辑视图Edit view:
FormView -------------- 显示一个form表单
CreateView ------------ 创建一个对象
UpdateView ------------更新对象
DeleteView --------------删除对象
5 例,路由代码
path('', views.IndexView.as_view(), name='index'),
视图代码
class IndexView(generic.ListView):
template_name = 'polls/index.html'
context_object_name = 'latest_question_list'
def get_queryset(self):
return Question.objects.order_by('-pub_date')[:5]
6 小贴士 6-1通用视图实际上 是类视图的一种,Django类视图的完整架构还是很庞大的。笔者只是提纲挈领,有兴趣 可以试着搜索“使用Django通用视图的get_queryset, get_context_data和get_object等方法”深入学习。
6-2 笔者在看一些程序员在做PHP后台维护时,数据库经常被SQL注入,其实简单点使用addslashes()函数就能解决大部分问题。
python3.7 中使用django-celery 完成异步任务python 虚拟环境管理工具
错误提出及讨论:
解决方案:
运行python manage.py celery worker -l INFO时报错:
参考:
解决方案:
说明:这是因为在python 3.7中将async作为了关键字,所以当 py 文件中出现类似from . import async, base这类不符合python语法的语句时,Python会报错。
解决:
Django配置Celery执行异步和同步任务(tasks))celery是一个基于python开发的简单、灵活且可靠的分布式任务队列框架,支持使用任务队列的方式在分布式的机器/进程/线程上执行任务调度。用典型的生产者-消费者模型,主要由三部分组成:
比如系统上线前后台批量导入历史数据,发送短信、发送邮件等耗时的任务
1.安装RabbitMQ,这里我们使用RabbitMQ作为broker,安装完成后默认启动了,也不需要其他任何配置
Ubuntu linux安装
CentOS Linux 安装
苹果mac 安装需要配置
配置环境变量 (苹果用户)
启动rabbitmq-server
2.安装celery
3.celery用在django项目中,django项目目录结构(简化)如下
4.创建 oa/celery.py 主文件
5.在 oa/__init__.py 文件中增加如下内容,确保django启动的时候这个能够被加载到
6.各应用创建tasks.py文件,这里为 users/tasks.py
7.views.py中引用使用这个tasks异步处理
8.启动celery
9.这样在调用post这个方法时,里边的add就可以异步处理了
定时任务的使用场景就很普遍了,比如我需要定时发送报告给老板~
1. oa/celery.py 文件添加如下配置以支持定时任务crontab
3.启动celery beat,celery启动了一个beat进程一直在不断的判断是否有任务需要执行
django中异步任务除了celery还有什么?轻量级的异步任务,例如简单的定时任务可以用apscheduler或linux本身的crontab实现
重量级的异步任务还是选用Celery+Redis最合适。
Django中怎么使用django-celery完成异步任务许多Django应用需要执行异步任务, 以便不耽误 request的执行. 我们也可以选择许多方法来完成异步任务, 使用Celery是一个比较好的选择, 因为Celery
有着大量的社区支持, 能够完美的扩展, 和Django结合的也很好. Celery不仅能在Django中使用, 还能在其他地方被大量的使用. 因此一旦学会使用Celery, 我
们可以很方便的在其他项目中使用它.
1. Celery版本
本篇博文主要针对Celery 3.0.x. 早期版本的Celery可能有细微的差别.
2. Celery介绍
Celery的主要用处是执行异步任务, 可以选择延期或定时执行功能. 为什么需要执行异步任务呢?
第一, 设用户正发起一个request, 并等待request完成后返回. 在这一request后面的view功能中, 我们可能需要执行一段花费很长时间的程序任务, 这一时间
可能远远大于用户能忍受的范围. 当这一任务并不需要立刻执行时, 我们便可以使用Celery在后台执行, 而不影响用户浏览网页. 当有任务需要访问远程服务器完
成时, 我们往往都无法确定需要花费的时间.
第二则是定期执行某些任务. 比如每小时需要检查一下天气预报, 然后将数据储存到数据库中. 我们可以编写这一任务, 然后让Celery每小时执行一次. 这样我们
的web应用便能获取最新的天气预报信息.
我们这里所讲的任务task, 就是一个Python功能(function). 定期执行一个任务可以被认为是延时执行该功能. 我们可以使用Celery延迟5分钟调用function
task1, 并传入参数(1, 2, 3). 或者我们也可以每天运行该function.
我们偏向于将Celery放入项目中, 便于task访问统一数据库和Django设置.
当task准备运行时, Celery会将其放入列队queue中. queue中储存着可以运行的task的list. 我们可以使用多个queue, 但为了简单, 这里我们只使用一个.
将任务task放入queue就像加入todo list一样. 为了使task运行, 我们还需要在其他线程中运行的苦工worker. worker实时观察着代运行的task, 并逐一运行这
些task. 你可以使用多个worker, 通常他们位于不同服务器上. 同样为了简单起见, 我们这只是用一个worker.
我们稍后会讨论queue, worker和另外一个十分重要的进程, 接下来我们来动动手:
3. 安装Celery
我们可以使用pip在vietualenv中安装:
pip install django-celery
4. Django设置
我们暂时使用django runserver来启动celery. 而Celery代理人(broker), 我们使用Django database broker implementation. 现在我们只需要知道Celery
需要broker, 使用django自身便可以充当broker. (但在部署时, 我们最好使用更稳定和高效的broker, 例如Redis.)
在settings.py中:
import djcelery
djcelery.setup_loader()
BROKER_URL = 'django://'
...
INSTALLED_APPS = (
...
'djcelery',
'kombu.transport.django',
...
)
第一二项是必须的, 第三项则告诉Celery使用Django项目作为broker.
在INSTALLED_APPS中添加的djcelery是必须的. kombu.transport.django则是基于Django的broker
最后创建Celery所需的数据表, 如果使用South作为数据迁移工具, 则运行:
python manage.py migrate
否则运行: (Django 1.6或Django 1.7都可以)
python manage.py syncdb
5. 创建一个task
正如前面所说的, 一个task就是一个Pyhton function. 但Celery需要知道这一function是task, 因此我们可以使用celery自带的装饰器decorator: @task. 在
django 目录中创建taske.py:
from celery import task
@task()
def add(x, y):
return x + y
当settings.py中的djcelery.setup_loader()运行时, Celery便会查看所有INSTALLED_APPS中目录中的tasks.py文件, 找到标记为task的function, 并
将它们注册为celery task.
将function标注为task并不会妨碍他们的正常执行. 你还是可以像平时那样调用它: z = add(1, 2).
6. 执行task
让我们以一个简单的例子作为开始. 例如我们希望在用户发出request后异步执行该task, 马上返回response, 从而不阻塞该request, 使用户有一个流畅的访问
过程. 那么, 我们可以使用.delay, 例如在在views.py的一个view中:
from my.tasks import add
...
add.delay(2, 2)
...
Celery会将task加入到queue中, 并马上返回. 而在一旁待命的worker看到该task后, 便会按照设定执行它, 并将他从queue中移除. 而worker则会执行以下代
码:
import my.tasks.add
my.tasks.add(2, 2)
7. 关于import
这里需要注意的是, 在impprt task时, 需要保持一致. 因为在执行djcelery.setup_loader()时, task是以INSTALLED_APPS中的名,
加.tasks.function_name注册的, 如果我们由于python path不同而使用不同的引用方式时(例如在tasks.py中使用from myproject.my.tasks import
add形式), Celery将无法得知这是同一task, 因此可能会引起奇怪的bug.
8. 测试
a. 启动worker
正如之前说到的, 我们需要worker来执行task. 以下是在开发环境中的如何启动worker:
首先启动terminal, 如同开发django项目一样, 激活virtualenv, 切换到django项目目录. 然后启动django自带web服务器: python manage.py runserver.
然后启动worker:
python manage.py celery worker --loglevel=info
此时, worker将会在该terminal中运行, 并显示输出结果.
b. 启动task
打开新的terminal, 激活virtualenv, 并切换到django项目目录:
$ python manage.py shell
from my.tasks import add
add.delay(2, 2)
此时, 你可以在worker窗口中看到worker执行该task:
[2014-10-07 08:47:08,076: INFO/MainProcess] Got task from broker: my.tasks.add[e080e047-b2a2-43a7-af74-d7d9d98b02fc]
[2014-10-07 08:47:08,299: INFO/MainProcess] Task my.tasks.add[e080e047-b2a2-43a7-af74-d7d9d98b02fc] succeeded in 0.183349132538s: 4
9. 另一个例子
下面我们来看一个更为真实的例子, 在views.py和tasks.py中:
# views.py
from my.tasks import do_something_with_form_data
def view(request):
form = SomeForm(request.POST)
if form.is_valid():
data = form.cleaned_data
# Schedule a task to process the data later
do_something_with_form_data.delay(data)
return render_to_response(...)
# tasks.py
@task
def do_something_with_form_data(data):
call_slow_web_service(data['user'], data['text'], ...)
10. 调试
由于Celery的运行需要启动多个部件, 我们可能会漏掉一两个. 所以我们建议:
使用最简单的设置
使用python debug和logging功能显示当前的进程
11. Eager模式
如果在settings.py设置:
CELERY_ALWAYS_EER = True
那么Celery便以eager模式运行, 则task便不需要加delay运行:
# 若启用eager模式, 则以下两行代码相同
add.delay(2, 2)
add(2, 2)
12. 查看queue
因为我们使用了django作为broker, queue储存在django的数据库中. 这就意味着我们可以通过django admin查看该queue:
# admin.py
from django.contrib import admin
from kombu.transport.django import models as kombu_models
admin.site.register(kombu_models.Message)
13. 检查结果
每次运行异步task后, Celery都会返回AsyncResult对象作为结果. 你可以将其保存, 然后在将来查看该task是否运行成功和返回结果:
# views.py
result = add.delay(2, 2)
...
if result.ready():
print "Task has run"
if result.successful():
print "Result was: %s" % result.result
else:
if isinstance(result.result, Exception):
print "Task failed due to raising an exception"
raise result.result
else:
print "Task failed without raising exception"
else:
print "Task has not yet run"
14. 定期任务
还有一种Celery的常用模式便是执行定期任务. 执行定期任务时, Celery会通过celerybeat进程来完成. Celerybeat会保持运行, 一旦到了某一定期任务需要执
行时, Celerybeat便将其加入到queue中. 不像worker进程, Celerybeat只有需要一个即可.
启动Celerybeat:
python manage.py celery beat
使Celery运行定期任务的方式有很多种, 我们先看第一种, 将定期任务储存在django数据库中. 即使是在django和celery都运行的状态, 这一方式也可以让我们
方便的修改定期任务. 我们只需要设置settings.py中的一项便能开启这一方式:
# settings.py
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
关于django如何实现异步视图和django 异步orm的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。
导读:很多朋友问到关于Python有多少版本的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!
python有几个版本Python的3.0版本,常被称为Python3000,或简称Py3k。相对于Python的早期版本,这是一个较大的升级。
为了不带入过多的累赘,Python3.0在设计的时候没有考虑向下相容。
许多针对早期Python版本设计的程式都无法在Python3.0上正常执行。
为了照顾现有程式,Python2.6作为一个过渡版本,基本使用了Python2.x的语法和库,同时考虑了向Python3.0的迁移,允许使用部分
Python3.0的语法与函数。
python学习网,免费的python学习网站,欢迎在线学习!
新的Python程式建议使用Python3.0版本的语法。
除非执行环境无法安装Python3.0或者程式本身使用了不支援Python3.0的第三方库。目前不支援Python3.0的第三方库有Twisted,
py2exe,PIL等。
大多数第三方库都正在努力地相容Python3.0版本。即使无法立即使用Python3.0,也建议编写相容Python3.0版本的程式,然后使用
Python2.6,Python2.7来执行。
python3.6有几个版本?
python3.6有12个版本,分别是3.6.0、3.6.1、3.6.2、3.6.3、3.6.4、3.6.5、3.6.7、3.6.8、3.6.9、3.6.10、3.6.11。
我们可以在python中查看python3.6各个版本的信息:
更多Python知识请关注Python自学网
小黑教育计算机二级python软件用的python是什么版本?使用的最古老的python3.0版本,没有信息提示和命令提示的版本。
考试大纲
先说说我们考试的题型,我讲的可能稍微会细一点,主要是照顾小白同学,大佬不喜欢请绕道,
一:考试环境
1.windows7操作系统
这个大家不陌生,机房里的电脑大多都是windows7
2.python3.4.2--3.5.3版本
我当时练习使用的是3.5.2,是这样,有的同学会问,有很高的版本为什么不用,对很高的版本用起来的确好用,我们开发项目的时候当然也会使用最高版本的,但是考试就要求是使用这个,python3.4.2--3.5.3和更高版本的python最大的区别就是,他基本上没有什么内容,例如,你想使用一个文本的打印操作,打印就是print,你print忘记怎么拼写了,那你就是凉了。但是高版本的时候,当你输入pr的时候就会出现print,包括一些其他的命令,不过也没有很难的代码,熟练了什么都不是问题。
3.IDLE开发环境
python解释器自带的IDLE开发环境,也是考试的环境。备考来说,不建议大家使用其他的环境。
二:题型分析
单项选择题(40*1分)
回答这一部分题时,你的键盘时锁住的,只有鼠标可以点来点去。
前十道题是公共基础知识
这一部分题,所有考二级的同学都是一样的,即使你边上那个考office的女朋友。
接下来30道题就是python的内容
其中含有
python的特点,保留字,变量命名,字符串语法,输入输出语法格式,数字类型,基本语法,分支结构,异常处理,内置函数,切片操作,开关文件操作,第三方库,字典,集合,列表等等等等,但大概就是这些
操作题(3*5分+10分+15分+20分=60分)
这一部分题开启之后选择题将不能在进行作答,在回答这部分题时可以时刻调出你的运行环境测试你的程序是不是编程正确。
基本编程题(3*5分)
这一部分的题基本上属于送分题,一般包括字符串按照格式打印,字符串进行一些语法上的操作输出一下,对数据类型进行的一些操作在输出,或者调用一个jieba库,用其中的一个分词的语法就可以轻松完成,这一部分题,都会给你一个标准的测试结果,你运行的时候输入考题中的测试,运行出来之后和考题中的结果就可以确定自己是不是正确。。
简单应用题(10分+15分)
考查考生利用turtle库来绘制一个图形,比如平行四边形呀,画一个有内切圆正方形呀,
这一部分题会让你填写代码,大体的代码已经有了,你需要把考题中的横线替换成你的代码,并能在考试的电脑上运行出和考题一样的结果就能保证结果正确无误。
另一部分题是关于统计字数的,统计票数的,多数是对文本文件进行的操作,输出的多数是统计之后的情况,这一部分没有正确的运行结果供考生参考。
综合应用题
与c语言不同,python二级考试的题目最后一道题分成了5+5+10分,分小题得分,完成一道题给一道题的分数
最后一道,一般是对文件的内容的管理,但是总体的套路都是一样的,只要掌握了基本模式,即使是最后一道压轴题也就可以手到擒来。
二:学习方法
练习和总结
不断的练习,不断的总结,当你有了一定的编程逻辑,了解了一定的python使用方法的时候,你就可以自己解决实际的问题了,考试的题目也可以迎刃而解,不断地练习是希望大家能够在考试之前解决大部分的问题,当遇到一个问题之后,我们能想到平时我们就解决的方法,而不是到了考场的时候现场做出来,120分钟的时间其实也不是十分的充裕,这也可能是我没有得到优秀的原因吧。
当然啦你要有一套题,考试这种东西刷题能解决99%的问题。咱也不知道是不是真的,反正咱也不敢问。
说到总结,这里要给大家一个忠告,在总结出一个比较好的习惯之后要不断的去实施去坚持,如在文件操作的时候写好open就随手把close写上,程序这种东西在学起来的时候,要知道他是如何实现的,要从根本入手,要知道为什么要这么做,比如你要知道是因为明天下雨所以天气预报才会说明天下雨,而不是天气预报说明天下雨,明天才会下雨,在刚开始学习编程的时候就是要不断的模仿,这一段我在ja的学习中真是体会的十分快乐,首先我承认我是一个比较笨的人,我在学习ja的时候,都开始学习接口的时候,我还是不知道输入的scanner输入到底怎么回事,我只知道要有这一行我下面在写实例化的名字的时候可以直接调用了,后来就能渐渐理解了,也知道要怎么写才能在之后输入,怎么写才能让程序看起来更加具有条理。
还要理解写一个大程序要逐步求精,比如我们再看别人写的程序的时候,就会发现十分的难看懂,后来你决定和他写出一个一模一样的程序,你发现根本不知道他的每一步在做什么,不能理解。这就是因为他在逐步求精的过程中,导致他的程序看上去越来越高大上,越来越精简,越来越难懂。例如我们的for循环,我们写这个循环的时候,是因为循环里的内容有规律可以寻找是吧,我们发现我们在长得差不多的程序上浪费了太多的时间时我们就会用循环的方法,使用循环的目的不是因为这里就是要用循环,而是这里的循环简单,当你遇到的每一个问题都能这么解决的时候会省去你十分多的时间和精力。
知识点是否需要总结,后续看有没有需要的同学,毕竟知识点这种东西书上都有好多
我坚信每一个考python二级的同学都是超级棒棒的同学,加油,祝你二级考试成功!!!
python现在更新到什么版本python现在的最新版本是3.6.1,他的是
Python的大版本分为python2和python3,这两者区别特性较大。通常官方的最新版本并非业内产品中的主流版本,现在业内要用Python2就是Python2.6居多,如果是Python3,一般是Python3.5。
现在python已经更新到哪个版本了已经更新到python3.10.2版本了。后附官方链接:
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
结语:以上就是首席CTO笔记为大家整理的关于Python有多少版本的相关内容解答汇总了,希望对您有所帮助!如果解决了您的问题欢迎分享给更多关注此问题的朋友喔~
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。